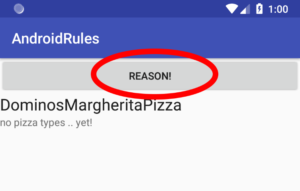
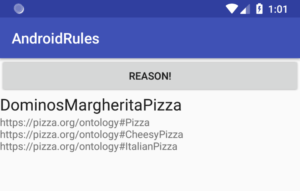
A frustrating issue that arises in rule-based reasoning is the plethora of rule formats. From a syntactic point of view, these formats can range from more or less similar (e.g., SPIN, Apache Jena, SPARQL-related) to wholly different ones (e.g., Datalog). This means that interesting rule engines, which you may want to compare regarding performance, may support different rule formats.
I ran into this issue when looking for a rule engine to implement Clinical Decision Support (CDS) for a mobile patient diary [1]. The heavyweight reasoning would still be deployed on the server side (were Drools was utilized), whereas urgent, time-sensitive reasoning (e.g., in response to new vital signs) would deployed on the mobile client.
|
|
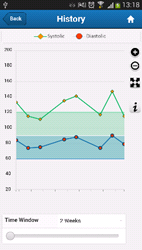 |
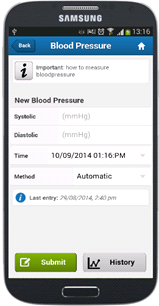
Since the mobile patient diary was going to be developed using Apache Cordova, I looked at both Java and JavaScript rule engines. I ported some reasoners manually to the Android platform, including some OWL reasoners (Roberto Yus did the same for a similar project). If you’re interested, all the benchmarked Android reasoners can be found here; regarding JavaScript reasoners, I compared the RDFQuery, RDFStore-JS (outfitted with naive reasoning) and Nools reasoners; benchmark results were reported in the literature [2-4]. In the context of this work, I also worked on optimizing OWL2 RL [4], a partial rule-based axiomatization of OWL2 for ontology reasoning, which I posted about before.
Ideally, I wanted a solution where I only needed to maintain a single ruleset for a given purpose (e.g., for CDS or OWL2 RL reasoning), which could then be converted to any other rule format when needed. I chose SPARQL Construct as the input format since SPARQL is well understood by most Semantic Web / Linked Data developers. Further, the SPARQL Inferencing Notation (SPIN) easily allows storing SPARQL queries together with the domain model.
To support this solution, I developed a simple web service for converting SPARQL Construct rules to Datalog, Apache Jena format and Nools format. Note that the Nools format is very similar to the Drools format – so it may be used to convert to Drools rules as well (given some adjustments). Further, the service can convert RDF data to the Datalog and Nools formats as well.
Note that this conversion may be far from perfect – since I focused solely on the language features that I needed at the time. Also, this is a limited number of formats that were motivated by my needs at the time. So, feel free to contribute to the project!
References
[1] W. Van Woensel, P.C. Roy, S.R. Abidi, S.S.R. Abidi, A Mobile and Intelligent Patient Diary for Chronic Disease Self-Management, in: Stud Heal. Technol Inf., 2015: pp. 118–122. doi:10.3233/978-1-61499-564-7-118.
[2] Van Woensel, N. Al Haider, P.C. Roy, A.M. Ahmad, S.S.R. Abidi, A comparison of mobile rule engines for reasoning on semantic web based health data, in: Proc. – 2014 IEEE/WIC/ACM Int. Jt. Conf. Web Intell. Intell. Agent Technol. – Work. WI-IAT 2014, 2014. doi:10.1109/WI-IAT.2014.25.
[3] W. Van Woensel, N. Al Haider, A. Ahmad, S.S.R. Abidi, A Cross-Platform Benchmark Framework for Mobile Semantic Web Reasoning Engines, in: Semant. Web — ISWC 2014, 2014: pp. 389–408. doi:10.1007/978-3-319-11964-9_25.
[4] W. Van Woensel, S. S. R. Abidi, Benchmarking Semantic Reasoning on Mobile Platforms: Towards Optimization Using OWL2 RL, in: Semantic Web Journal, Forthcoming (2018).